KYLIN、DRUID、CLICKHOUSE是目前主流的OLAP引擎,本文尝试从数据模型和索引结构两个角度,分析这几个引擎的核心技术,并做简单对比。在阅读本文之前希望能对KYLIN、DRUID、CLICKHOUSE有所理解。
1. KYLIN数据模型
Kylin的数据模型本质上是将二维表(Hive表)转换为Cube,然后将Cube存储到HBase表中,也就是两次转换。详细信息可以参我的另一篇文章《Kylin数据模型》
第一次转换,其实就是传统数据库的Cube化,Cube由CuboId组成,下图每个节点都被称为一个CuboId,CuboId表示固定列的数据数据集合,比如“ AB” 两个维度组成的CuboId的数据集合等价于以下SQL的数据集合:
select A, B, sum(M), sum(N) from table group by A, B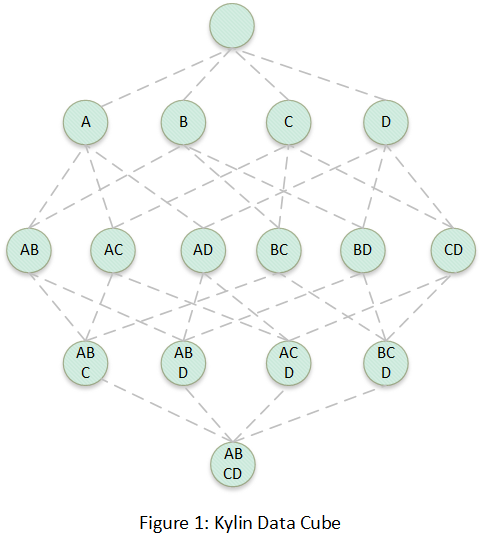
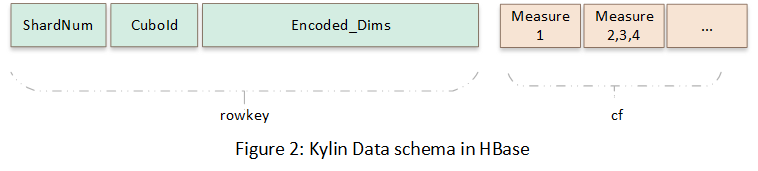
第二次转换,是将Cube中的数据存储到HBase中,转换的时候CuboId和维度信息序列化到rowkey,度量列组成列簇。在转换的时候数据进行了预聚合。下图展示了Cube数据在HBase中的存储方式。
2. KYLIN索引结构
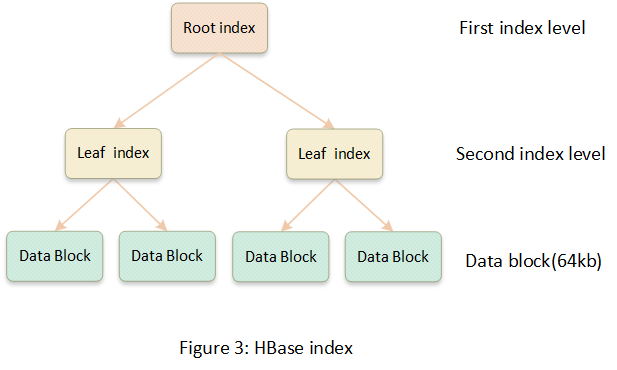
因为Kylin将数据存储到HBase中,所以kylin的数据索引就是HBase的索引。HBase的索引是简化版本的B+树,相比于B+树,HFile没有对数据文件的更新操作。
HFile的索引是按照rowkey排序的聚簇索引,索引树一般为二层或者三层,索引节点比MySQL的B+树大,默认是64KB。数据查找的时候通过树形结构定位到节点,节点内部数据是按照rowkey有序的,可以通过二分查找快速定位到目标。
KYLIN小结:适用于聚合查询场景;因为数据预聚合,Kylin可以说是最快的查询引擎(group-by查询这样的复杂查询,可能只需要扫描1条数据);kylin查询效率取决于是否命中CuboId,查询波动较大;HBase索引有点类似MySQL中的联合索引,维度在rowkey中的排序和查询维度组合对查询效率影响巨大; 所以Kylin建表需要业务专家参与。
4. DRUID数据模型
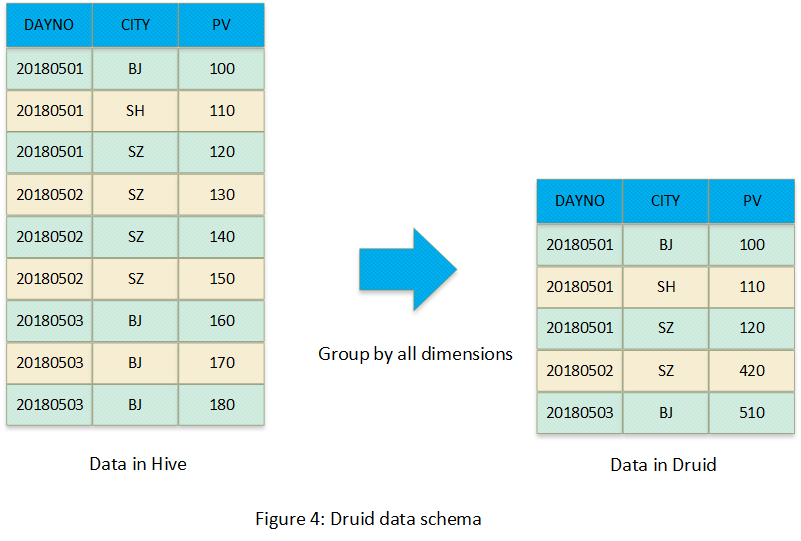
Druid数据模型比较简单,它将数据进行预聚合,只不过预聚合的方式与Kylin不同,kylin是Cube化,Druid的预聚合方式是将所有维度进行Group-by,可以参考下图:
5. DRUID索引结构
Druid索引结构可以参考我的另一篇文章《Druid存储结构》,它使用自定义的数据结构,整体上它是一种列式存储结构,每个列独立一个逻辑文件(实际上是一个物理文件,在物理文件内部标记了每个列的start和offset)。对于维度列设计了索引,它的索引以Bitmap为核心。下图为“city”列的索引结构:
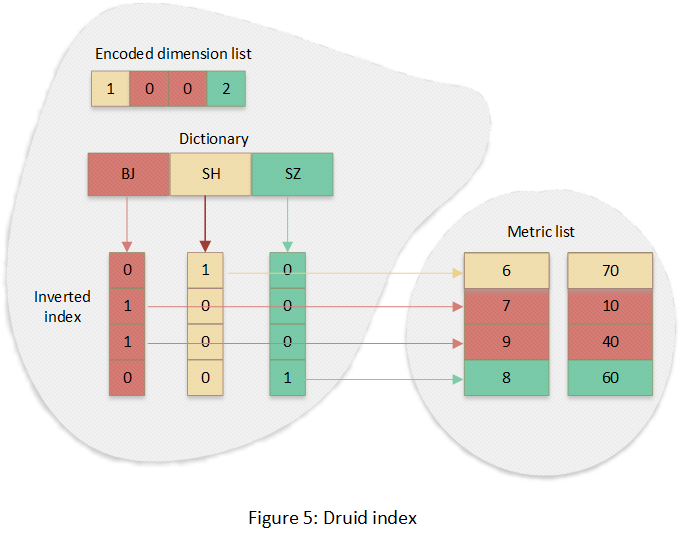
首先将该列所有的唯一值排序,并生成一个字典,然后对于每个唯一值生成一个Bitmap,Bitmap的长度为数据集的总行数,每个bit代表对应的行的数据是否是该值。Bitmap的下标位置和行号是一一对应的,所以可以定位到度量列,Bitmap可以说是反向索引。同时数据结构中保留了字典编码后的所有列值,其为正向的索引。
那么查询如何使用索引呢?以以下查询为例:
select site, sum(pv) from xx where date=2020-01-01 and city='bj' group by site- city列中二分查找dictionary并找到’bj’对应的bitmap
- 遍历city列,对于每一个字典值对应的bitmap与‘bj’的bitmap做与操作
- 每个相与后的bitmap即为city=’bj’查询条件下的site的一个group的pv的索引
- 通过索引在pv列中查找到相应的行,并做agg
- 后续计算
DRUID小结:Druid适用于聚合查询场景但是不适合有超高基维度的场景;存储全维度group-by后的数据,相当于只存储了KYLIN Cube的Base-CuboID;每个维度都有创建索引,所以每个查询都很快,并且没有类似KYLIN的巨大的查询效率波动。
7. CLICKHOUSE索引结构(只讨论MergeTree引擎)
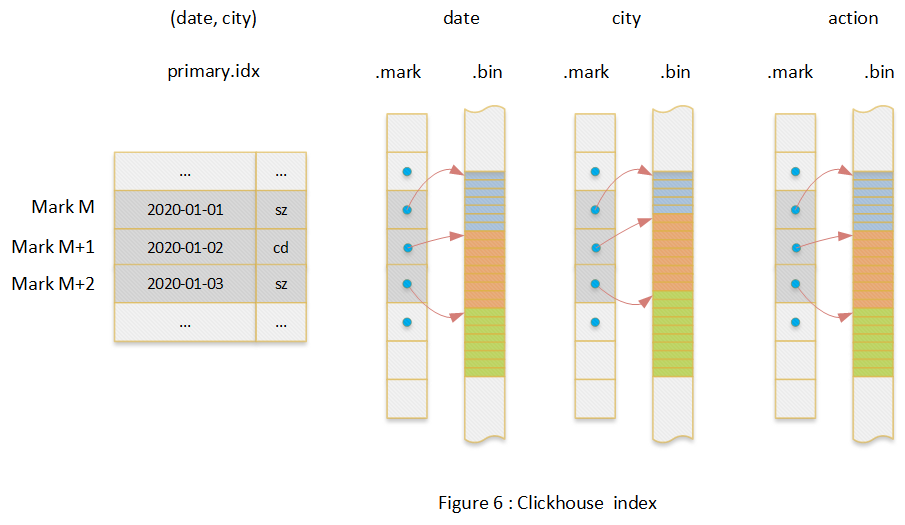
因为Clickhouse数据模型就是普通二维表,这里不做介绍,只讨论索引结构。整体上Clickhouse的索引也是列式索引结构,每个列一个文件。Clickhouse索引的大致思路是:首先选取部分列作为索引列,整个数据文件的数据按照索引列有序,这点类似MySQL的联合索引;其次将排序后的数据每隔8194行选取出一行,记录其索引值和序号,注意这里的序号不是行号,序号是从零开始并递增的,Clickhouse中序号被称作Mark’s number;然后对于每个列(索引列和非索引列),记录Mark’s number与对应行的数据的offset。
下图中以一个二维表(date, city, action)为例介绍了整个索引结构,其中(date,city)是索引列。
那么查询如何使用索引呢?以以下查询为例:
select count(distinct action) where date=toDate(2020-01-01) and city=’bj’- 二分查找primary.idx并找到对应的mark’s number集合(即数据block集合)
- 在上一步骤中的 block中,在date和city列中查找对应的值的行号集合,并做交集,确认行号集合
- 将行号转换为mark’s number 和 offset in block(注意这里的offset以行为单位而不是byte)
- 在action列中,根据mark’s number和.mark文件确认数据block在bin文件中的offset,然后根据offset in block定位到具体的列值。
- 后续计算
该实例中包含了对于列的正反两个方向的查找过程。反向:查找date=toDate(2020-01-01) and city=’bj’数据的行号;正向:根据行号查找action列的值。对于反向查找,只有在查找条件匹配最左前缀的时候,才能剪枝掉大量数据,其它时候并不高效。
Clickhouse小结:MergeTree Family作为主要引擎系列,其中包含适合明细数据的场景和适合聚合数据的场景;Clickhouse的索引有点类似MySQL的联合索引,当查询前缀元组能命中的时候效率最高,可是一旦不能命中,几乎会扫描整个表,效率波动巨大;所以建表需要业务专家,这一点跟kylin类似。
小结
- KYLIN、DRUID只适合聚合场景,CLICKHOUSE适合明细和聚合场景
- 聚合场景,查询效率排序:KYLIN > DRUID > CLICKHOUSE
- KYLIN、CLICKHOUSE建表都需要业务专家参与
- KYLIN、CLICKHOUSE查询效率都可能产生巨大差异
- CLICKHOUSE在向量化方面做得的最好,DRUID少量算子支持向量化、KYLIN目前还不支持向量化计算。
本作品采用 知识共享署名 4.0 国际许可协议 进行许可, 转载时请注明原文链接。